Yuxuan Mu
I’m a Ph.D. student at the GrUVi Lab at Simon Fraser University, advised by Professor |

|
ResearchMy work centers around 3D character motion—spanning estimation, generation, physics simulation, and control. I’m particularly interested in bridging the gap between the physical and virtual worlds to enable richer perception, understanding, and interaction. To that end, I design generative models and reinforcement learning systems that leverage physics simulations to better capture and replicate human behavior and interactions. '*' indicates equal contribution. |

|
SMP: Reusable Score-Matching Motion Priors for Physics-Based Character ControlYuxuan Mu*, Ziyu Zhang*, Yi Shi*, Dun Yang, Minami Matsumoto, Kotaro Imamura, Guy Tevet, Chuan Guo, Michael Taylor, Chang Shu, Pengcheng Xi, Xue Bin Peng ACM Transactions on Graphics (Proc. SIGGRAPH), 2026 webpage / paper / video / code / SMP constructs reusable, modular reward models that evaluate motion naturalness and guide motor-controller training. |

|
StableMotion: Training Motion Cleanup Models with Unpaired Corrupted DataYuxuan Mu, Hung Yu Ling, Yi Shi, Ismael Baira Ojeda, Pengcheng Xi, Chang Shu, Fabio Zinno, Xue Bin Peng SIGGRAPH Asia, 2025 webpage / paper / video / code / 🧑🔧 You don’t need a clean dataset to train a motion cleanup model. StableMotion learns to fix corrupted motions directly from raw mocap data — no handcrafted data pairs, no synthetic artifact augmentation. |

|
MotionDreamer: One-to-More Motion Synthesis with Localized Generative Masked TransformerYilin Wang, Chuan Guo, Yuxuan Mu, Muhammad Gohar Javed, Xinxin Zuo, Li Cheng, Hai Jiang, Juwei Lu ICLR, 2025 webpage / paper / Localized masked modeling paradigm to learn motion internal patterns from one motion with arbitrary topology. |

|
GSD: View-Guided Gaussian Splatting Diffusion for 3D ReconstructionYuxuan Mu, Xinxin Zuo, Chuan Guo, Yilin Wang, Juwei Lu, Xiaofei Wu, Songcen Xu, Peng Dai, Youliang Yan, Li Cheng ECCV, 2024 webpage / paper / The first 3D diffusion model directly upon Gaussian Splatting for real‐world object reconstruction, with fine-grained view-guided conditioning. |
|
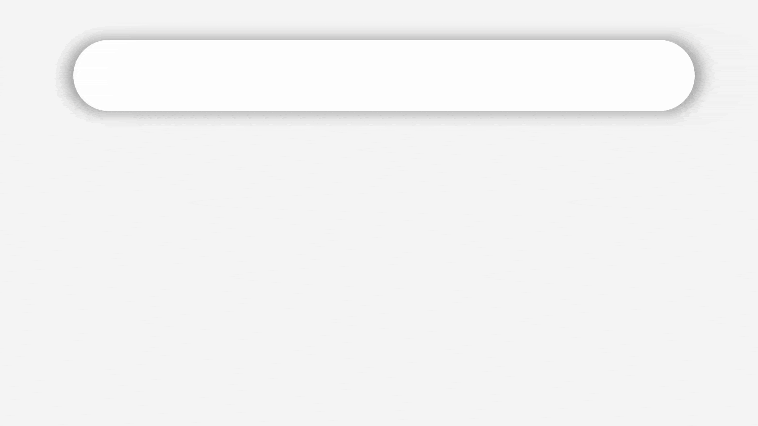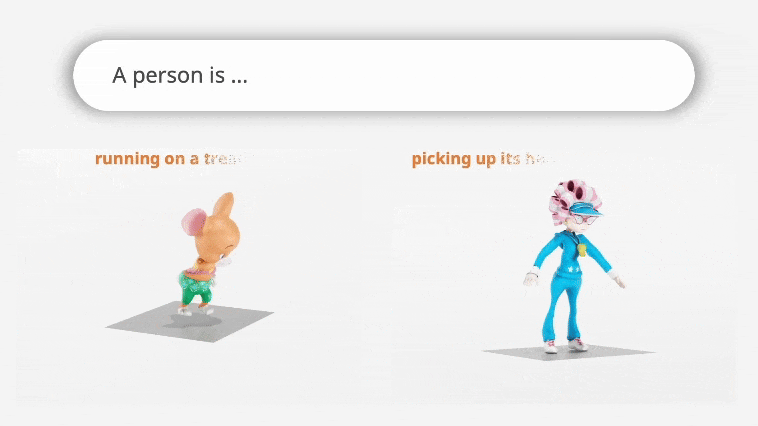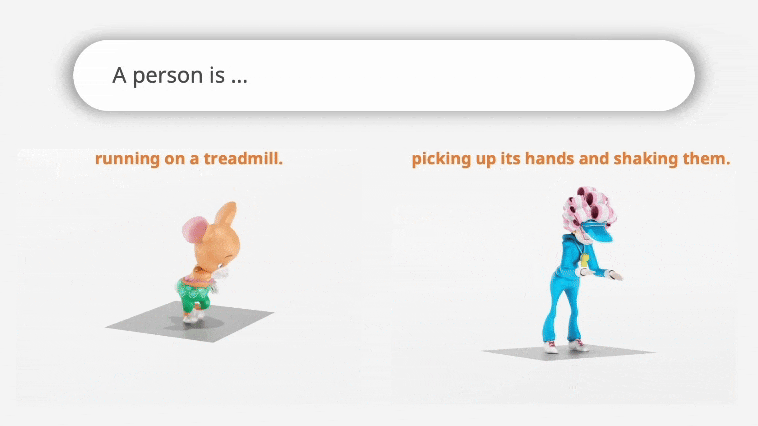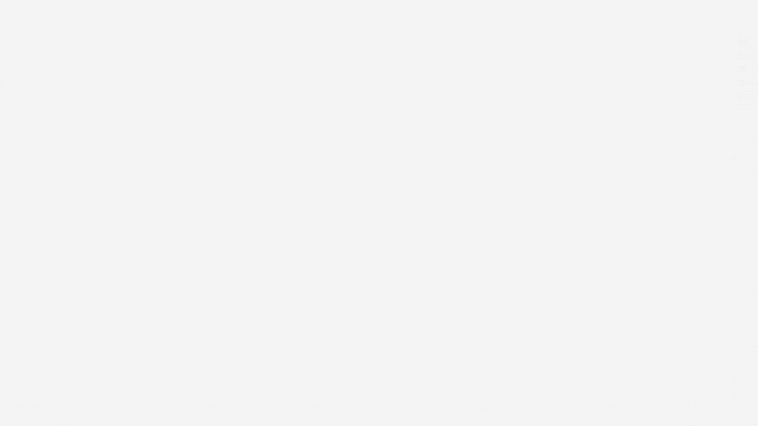
MoMask: Generative Masked Modeling of 3D Human MotionsChuan Guo*, Yuxuan Mu*, Muhammad Gohar Javed*, Sen Wang, Li Cheng CVPR, 2024 webpage / paper / code / demo / Star We introduce MoMask, a novel masked modeling frame work for text‐driven 3D human motion generation with a hierarchical quantization scheme. |
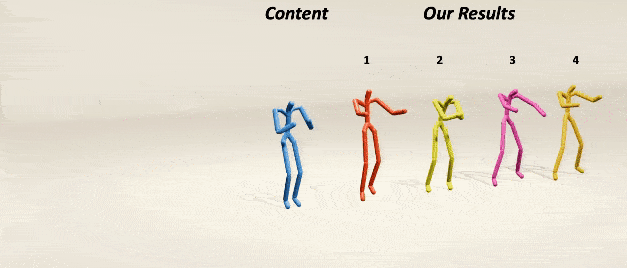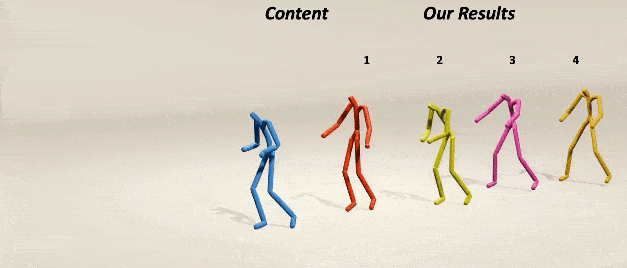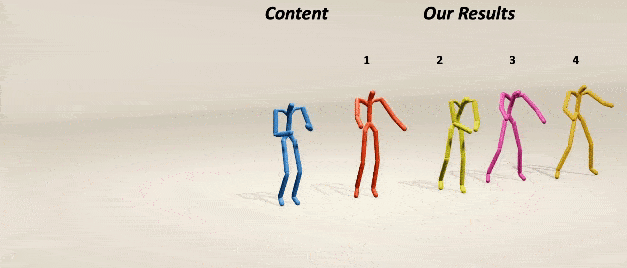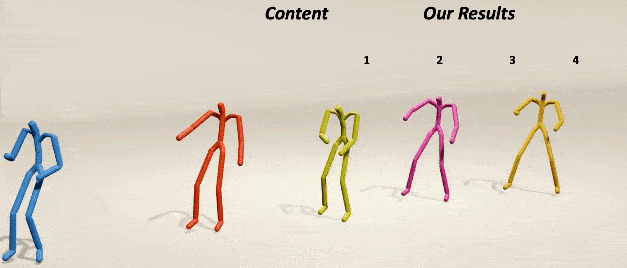
|
Generative Human Motion Stylization in Latent SpaceChuan Guo*, Yuxuan Mu*, Xinxin Zuo, Peng Dai, Youliang Yan, Juwei Lu, Li Cheng ICLR, 2024 webpage / paper / code / We propose a flexible motion style extraction and injection method from a generative perspective to solve the motion stylization task with probabilistic style space. |

|
RACon: Retrieval-Augmented Simulated Character Locomotion ControlYuxuan Mu, Shihao Zou, Kangning Yin, Zheng Tian, Li Cheng, Weinan Zhang, Jun Wang ICME (Oral), 2024 paper / We introduce an end-to-end hierarchical reinforcement learning method utilizes a task-oriented learnable retriever, a motion controller and a retrieval-augmented discriminator. |
|
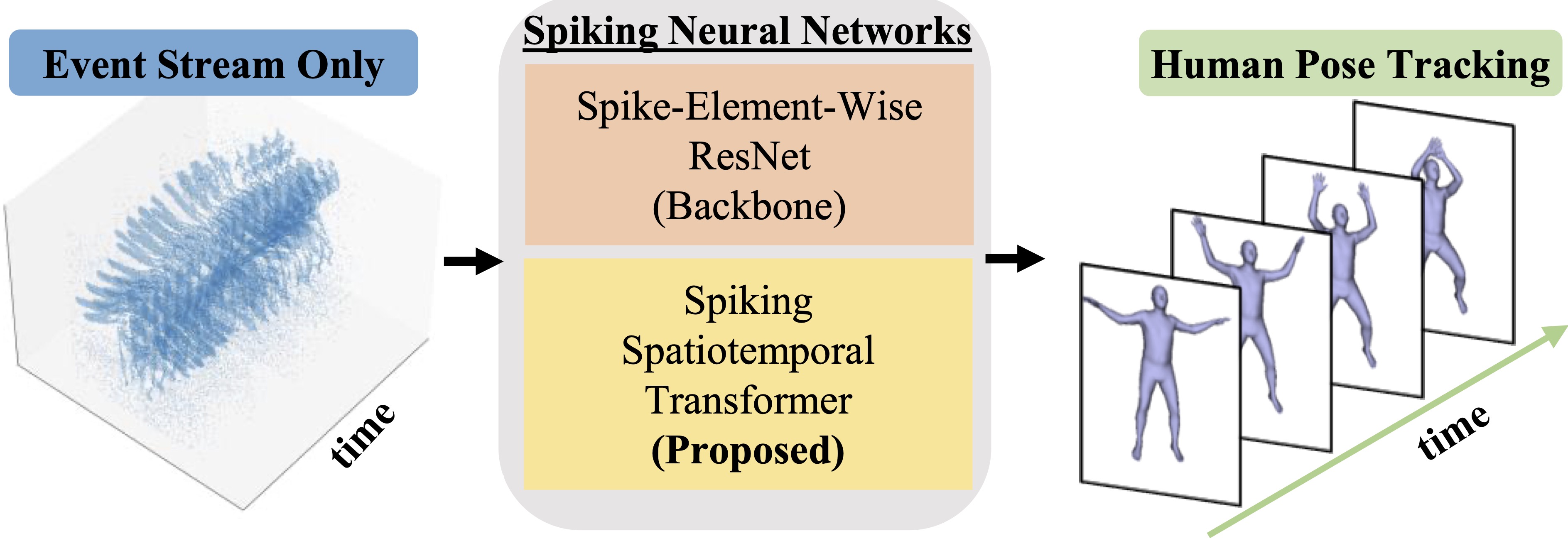
Event‐based Human Pose Tracking by Spiking Spatiotemporal TransformerShihao Zou, Yuxuan Mu, Xinxin Zuo, Sen Wang, Li Cheng IEEE TCSVT, 2023 paper / code / Our SNNs approach uses at most 19.1% of the computation and 3.6% of the energy costs consumed by the existing methods while achieves superior performance. |
|
Design and source code from Leonid Keselman's website |